Learning
What You Will Learn in This Chapter
How does neurofeedback actually teach the brain to change? This unit explores the learning processes that power neurofeedback training, from classical and operant conditioning to observational learning. You will discover how reinforcement schedules, shaping, and discrimination work together to help clients develop lasting self-regulation skills.
You will also examine the critical elements that make neurofeedback training effective, including readiness, repetition, reinforcement timing, and the importance of active client participation. These principles draw directly from decades of learning theory research and their practical application in the clinic.
Finally, you will see how a recent paper by Kerson, Sherlin, and Davelaar (2025) reframes neurofeedback as an engineered learning environment rather than a simple stream of information. This perspective shows why reinforcement schedules, feedback timing, and signal integrity decide what the nervous system actually learns, and why your role is closer to that of a learning coach than a technician. We will explore the physiological mechanisms by which the nervous system learns, neuroplasticity, in our Neurophysiology unit. Last, you will learn practical ways to keep reward tied to the right brain state and to help clients carry their new skills into everyday life.
BCIA Blueprint Coverage: This unit addresses I. Orientation to Neurofeedback - C. Overview of Principles of Human Learning as They Apply to Neurofeedback.
Neurofeedback teaches clients to self-regulate neuronal activity and the "state changes" that accompany it. This training draws on several learning processes, most notably operant conditioning and observational learning. Modern neurofeedback software applies powerful operant principles by selectively delivering visual, auditory, and tactile reinforcing stimuli in response to brain activity.
Consider how these principles work in practice. A movie plays when a child increases low-beta activity and decreases theta activity, providing positive reinforcement, a reward for producing the desired brain state. A score counter stops reversing when the child refocuses on a reading selection after several minutes of distraction, illustrating negative reinforcement, the removal of an unwanted outcome. As the child succeeds, the training goal becomes progressively more demanding through a process called shaping.
Sherlin et al. (2011) underscored the centrality of learning theory to neurofeedback practice: "It is our contention that future applications in clinical work, research, and development should not stray from the already-demonstrated basic principles of learning theory until empirical evidence demonstrates otherwise" (p. 292). This emphasis reminds us that effective neurofeedback is not simply a technology; it is a structured application of learning science.

BCIA Blueprint Coverage
This unit covers I. Orientation to Neurofeedback - C. Overview of Principles of Human Learning as They Apply to Neurofeedback.

The sections ahead address Three Main Types of Learning, Classical Conditioning, Operant Conditioning, Nonassociative Learning, Observational Learning, Critical Elements in Neurofeedback Training, and Designing the Learning Environment. Together, these topics will give you a comprehensive foundation in the learning science that underpins clinical neurofeedback.

Three Main Types of Learning
This section introduces the three main categories of learning and explains why two of them are especially relevant to neurofeedback. We can divide learning into three broad categories: associative, nonassociative, and observational. Of these, associative learning and observational learning matter most for neurofeedback. In associative learning, we form connections between stimuli, behaviors, or combinations of the two.
Associative learning serves a fundamental survival function: it enables us to predict future events based on past experience. Learning that event B reliably follows event A gives us precious time to prepare. Classical conditioning and operant conditioning are the two major forms of associative learning, and both play important roles in neurofeedback training (Cacioppo & Freberg, 2016).
Classical Conditioning
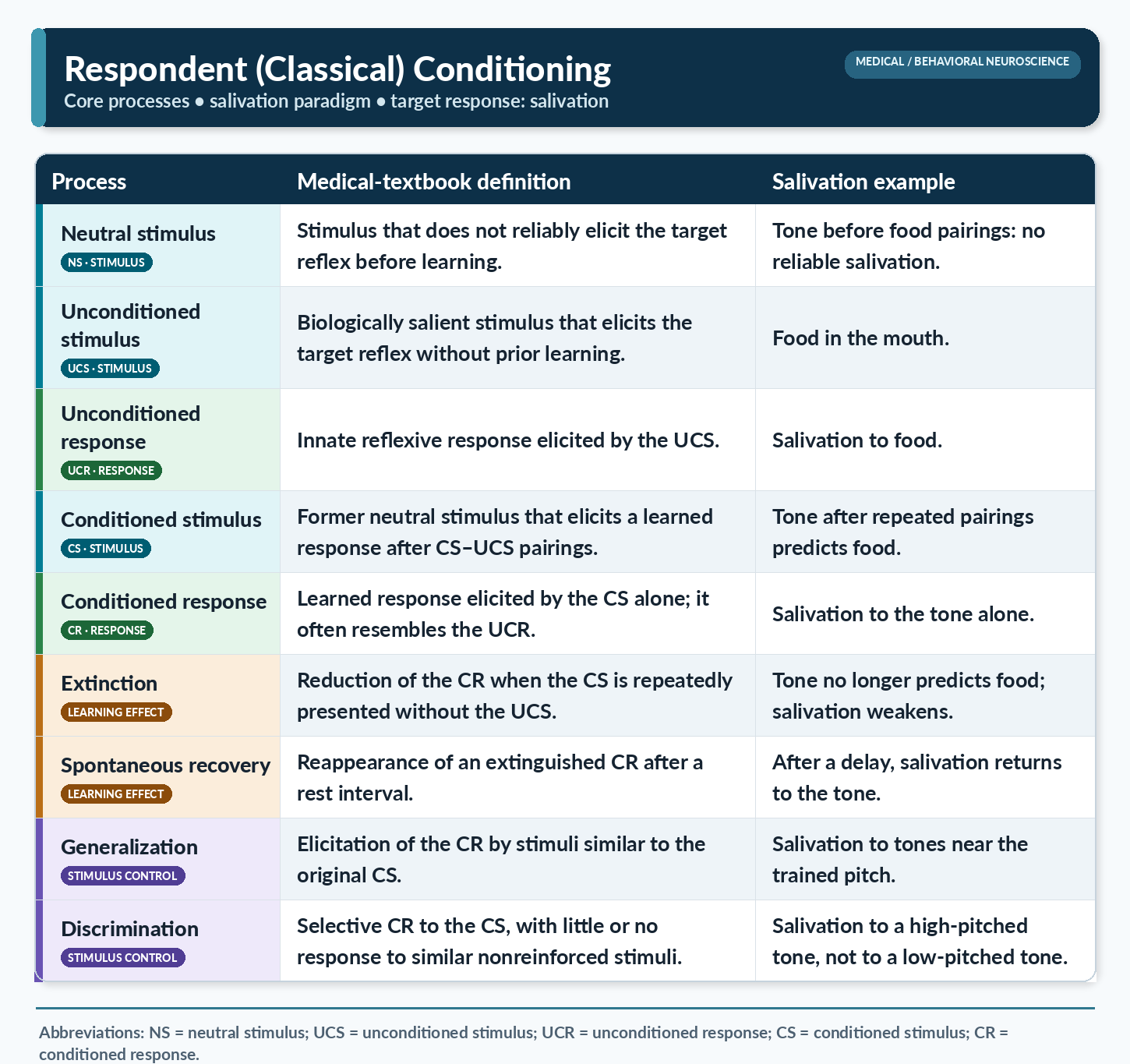
This section covers how classical conditioning works, its key terminology, and the processes of extinction, spontaneous recovery, generalization, and discrimination. Ivan Pavlov first demonstrated classical conditioning in 1927 through his landmark research with dogs. Due to imprecise English translations of his Russian text, the field adopted the adjectives conditioned and unconditioned rather than Pavlov's original conditional and unconditional. We will use the conventional terminology throughout this unit to avoid confusion.

Classical conditioning (also called respondent conditioning) is an unconscious associative learning process that builds connections between paired stimuli occurring close together in time. In Pavlov's laboratory, dogs learned that if stimulus A (a ringing bell) occurred, stimulus B (food) would reliably follow. This ability to predict the future from experience is crucial to survival because it provides time to prepare for what comes next.
Before conditioning, Pavlov's dogs salivated (an unconditioned response, or UCR) when they encountered food (an unconditioned stimulus, or UCS), a reflexive reaction requiring no prior learning. The bell, at this stage, was a neutral stimulus (NS) that produced no salivation. Through repeated pairings of the bell with the arrival of food, the dogs learned that the bell reliably signaled feeding. The bell became a conditioned stimulus (CS) that elicited salivation, now termed a conditioned response (CR).
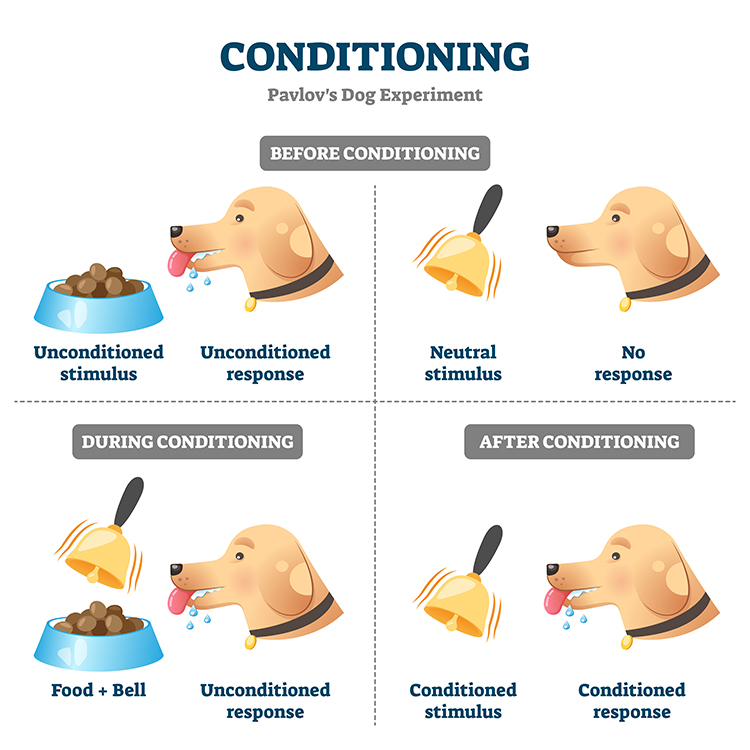
When the CS-CR association is disrupted because outcome B no longer consistently follows stimulus A, the CR may weaken or vanish altogether. This process is called extinction, a gradual decline in the learned response when the expected pairing no longer holds. In Pavlov's experiment, repeated trials without food following the bell reduced and eventually eliminated salivation. Extinction helps us adapt when our environment changes. For example, after a childhood bite teaches you to fear dogs, repeated safe encounters can weaken that conditioned fear until you enjoy their company again.
Importantly, Pavlov argued that extinction does not erase the original learning but rather reflects new learning that overrides it. The phenomenon of spontaneous recovery supports this view. In spontaneous recovery, an extinguished CR (such as salivation) reappears after a rest period without exposure to the CS. Dogs that had stopped salivating by the end of an extinction session began salivating again when the bell was presented in a subsequent session, suggesting that the original association persisted beneath the new, inhibitory learning.
Generalization and discrimination represent two sides of the same coin. In generalization, the CR spreads to stimuli that resemble the original CS. A dog conditioned to salivate to a high-pitched bell may also salivate to a lower-pitched bell. This process promotes survival by allowing us to extend what we learned about one threat (e.g., lions) to similar ones (e.g., tigers) without direct experience.
In discrimination, the organism learns to respond selectively, producing the CR to one stimulus but not to a similar one. Discrimination carries direct clinical relevance. When combat veterans return to civilian life, they must learn to distinguish between a CS that once signaled danger (gunfire) and a similar but benign stimulus (fireworks). This discrimination is often impaired in individuals diagnosed with post-traumatic stress disorder (PTSD), making it a meaningful target for clinical intervention.
Where does classical conditioning fit into neurofeedback training?
We may speculate that the interoceptive sense of feeling at ease, an unconditioned response that arises automatically in a safe environment or in the presence of a caring clinician's soothing voice, can also be cultivated across a series of neurofeedback sessions. As clients grow more fluent in producing the target feedback, they begin to feel good inside, and this pleasant internal state pairs repeatedly with the sights and sounds of the feedback display. Through that pairing, the once-neutral feedback stimuli become conditioned cues that can evoke the same calm, focused state on their own.
This mechanism may help explain how training effects travel beyond the clinic. When a client later recalls the auditory and visual cues from their sessions, those remembered stimuli can trigger a generalized conditioned response that supports calm, capable performance in the moment. A musician waiting backstage, a student opening an exam booklet, or a veteran steadying themselves in a crowded store can summon the conditioned state by bringing the training cues to mind. In this view, classical conditioning becomes a bridge that carries the benefits of neurofeedback into real-life settings and helps sustain them after clinic training ends.
Operant Conditioning
This section covers operant conditioning and its application to neurofeedback, including the four types of consequences, reinforcement criteria, shaping, and the goals of discrimination and generalization.
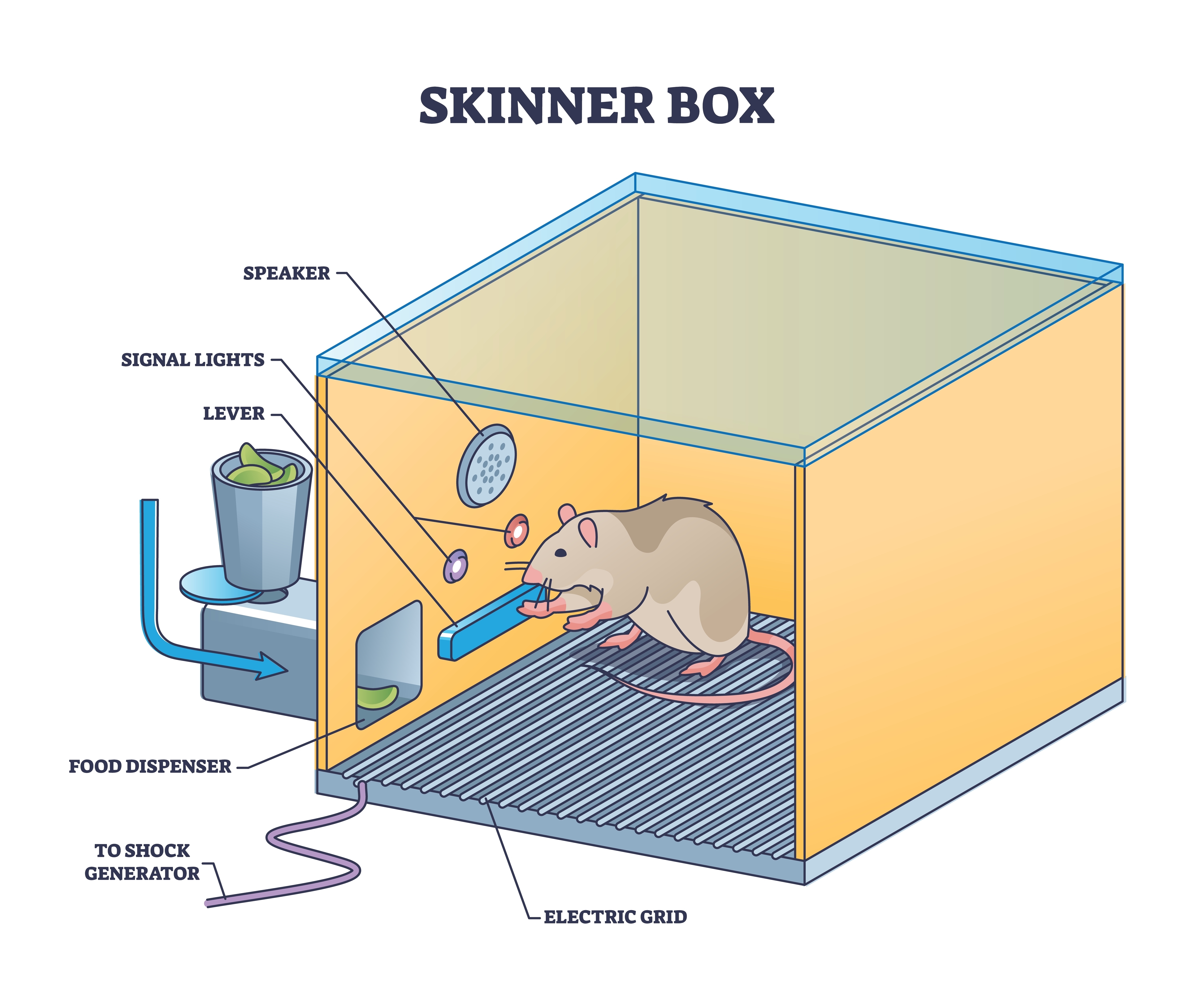
Edward Thorndike's (1913) law of effect established a foundational principle: the consequences of a behavior determine whether it becomes part of an organism's repertoire. In his puzzle-box experiments, cats learned to escape by repeating actions that led to freedom and abandoning those that did not. Operant conditioning builds on this insight. It is an unconscious associative learning process that modifies operant behavior (voluntary behavior that "operates" on the environment to produce an outcome) by manipulating the consequences that follow it (Miltenberger, 2016).
Operant conditioning differs from classical conditioning in a key respect. Where classical conditioning teaches the predictive relationship between two stimuli to modify involuntary responses, operant conditioning links a voluntary behavior to its consequences. This distinction is central to neurofeedback, which teaches self-regulation of neural activity and related state changes through the selective, real-time presentation of reinforcing stimuli, including visual, auditory, and tactile displays.
Operant conditioning always occurs within a situational context. The identifying characteristics of that situation are called discriminative stimuli, cues from the physical environment, as well as physical, cognitive, and emotional signals that tell us when to perform a particular behavior. For example, a traffic slowdown could serve as a discriminative stimulus signaling a client to practice effortless breathing.
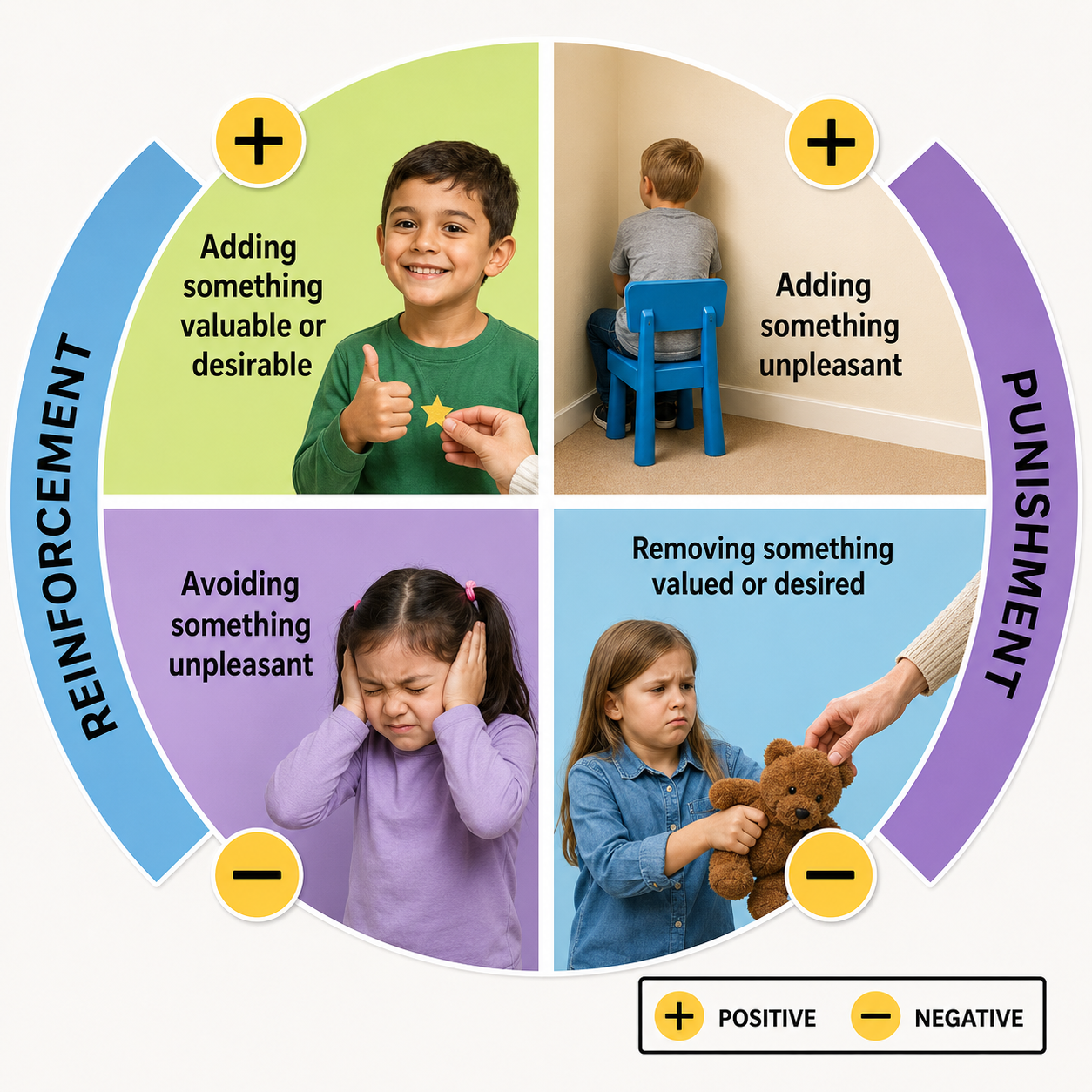
The consequences of operant behaviors either increase or decrease their frequency. B.F. Skinner proposed four types of consequences, organized along two dimensions: whether the consequence adds or removes something, and whether it strengthens or weakens behavior. Due to individual differences, we cannot predict in advance whether a particular consequence will reinforce or punish a behavior because these are not intrinsic properties of the stimulus. We can only determine a consequence's function by measuring its effect on the preceding behavior. In neurofeedback, the movie that motivates the strongest performance is the effective reinforcer, regardless of the clinician's personal preference (Cooper et al., 2019).
Positive reinforcement increases the frequency of a desired behavior by making a desirable outcome contingent on performing it. For example, a movie plays when a client diagnosed with attention deficit hyperactivity disorder (ADHD) increases low-beta and decreases theta activity. Negative reinforcement also increases a desired behavior, but it works by removing, postponing, or allowing the individual to avoid an unwanted outcome. An athlete's anxiety decreases when shifting from high-beta to low-beta activity, and this relief itself reinforces the brain state that produced it.
Positive punishment decreases or eliminates an undesirable behavior by pairing it with an unwanted consequence. Positive punishment decreases or eliminates an undesirable behavior by following it with an aversive consequence. A child's fidgeting, for instance, might add static to a favorite movie.. Negative punishment also reduces unwanted behavior, but by removing something the individual values. Oppositional behavior during a session could result in the clinician turning off a popular game.
Reinforcement Criteria
This subsection covers how reinforcement parameters (including schedule, timing, and artifact control) affect skill acquisition in neurofeedback. Current research continues to explore the optimal reinforcement criteria for neurofeedback training. Parameters such as reinforcement schedule, reward frequency, reinforcement delay, conflicting reinforcements, conflicting expectations, and environmental factors all markedly influence how well clients acquire new skills.
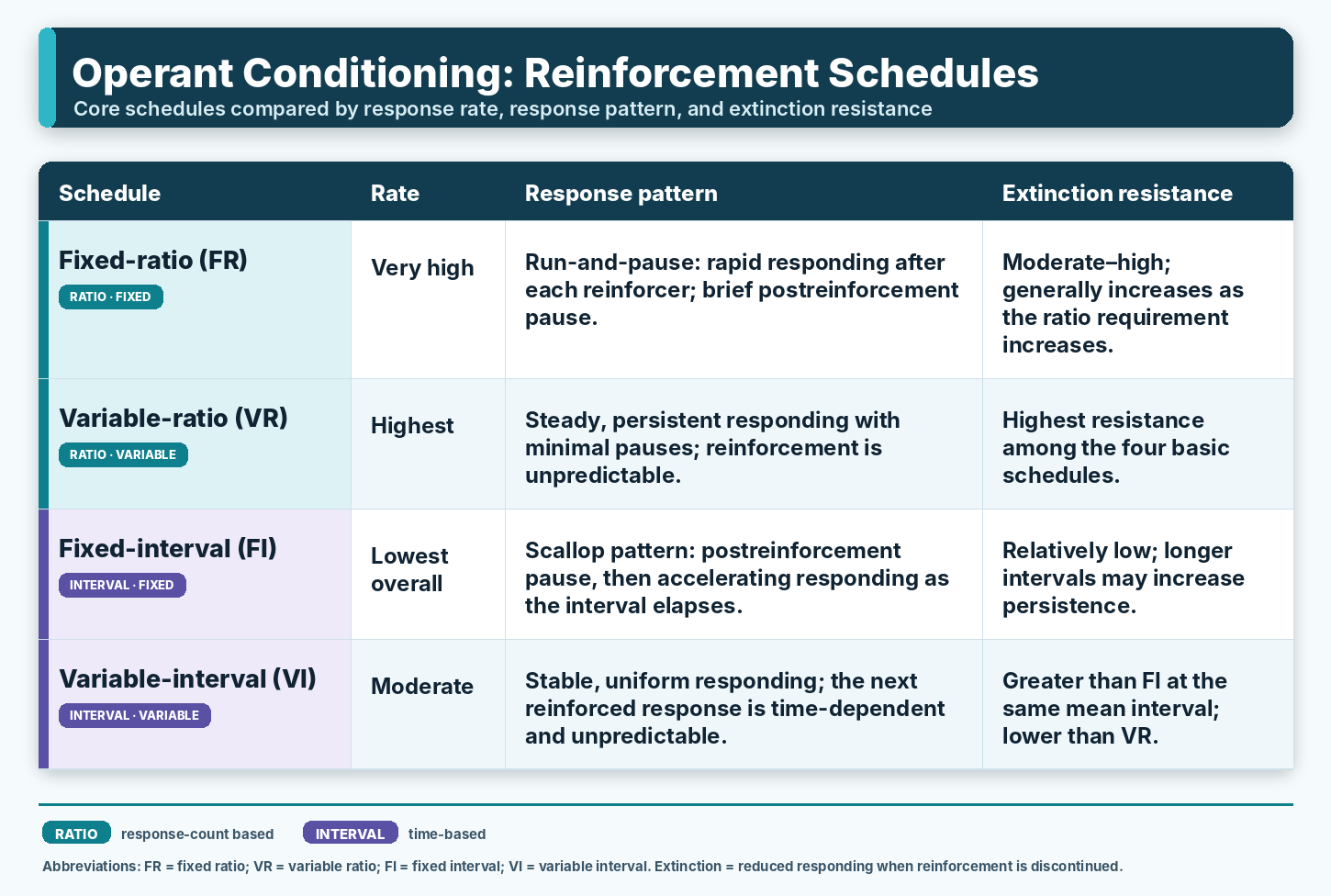
While continuous reinforcement, reinforcing every instance of the desired behavior, is effective during early skill acquisition, it becomes impractical as clients work to transfer skills beyond the clinic. Because real-world reinforcement is intermittent, partial reinforcement schedules, in which the desired behavior is reinforced only some of the time, become essential as training progresses. Partial schedules also protect against extinction, the decline in a behavior's frequency that occurs when reinforcement ceases entirely. Among partial schedules, variable reinforcement schedules, where reinforcement follows a variable number of responses (variable ratio) or a variable duration of time (variable interval), produce superior response rates compared to their fixed counterparts (Malott & Shane, 2013).
Brain rhythms are themselves a form of behavior, even if they are not the physical movement. Sherlin et al. (2011) emphasized that clinicians must understand the targeted brain rhythms and the underlying EEG neurophysiology to design effective reinforcement criteria. The sensorimotor rhythm (SMR), for example, consists of spindle bursts lasting at least 0.25 seconds. Criteria such as "time above threshold" or "duration of sustained reward" tailor feedback to the natural characteristics of the SMR rhythm, producing superior outcomes compared to simply reinforcing any momentary shift above an amplitude threshold. As Sherlin et al. (2011) advised: "For operant conditioning, it is very important to be aware of specifically 'what behavior' is being conditioned in order to achieve learning and to improve the specificity" (p. 300).
This specificity is especially critical in the context of EEG artifacts, false signals that masquerade as genuine brain electrical activity. The EEG signal is vulnerable to a wide range of biological artifacts (from the heart, eyes, respiration, and skeletal muscles) and environmental artifacts (50/60-Hz line noise, radiofrequency interference). Neurofeedback systems should therefore provide real-time artifact control. Clinicians must carefully monitor training to prevent "artifact-driven feedback," ensuring that they do not inadvertently reward changes in eye-blink frequency or frontalis muscle tension rather than genuine cortical activity. Effective artifact control increases training specificity and clinical success (Sherlin et al., 2011).
Shaping
Shaping, also known as the method of successive approximations, is the process of teaching new behaviors by progressively raising the criteria for reinforcement. A clinician begins by reinforcing spontaneous voluntary behaviors that approximate the target and then gradually increases the standard. For example, a clinician can progressively require lower theta-to-beta ratios before a movie plays, systematically guiding the client's brain activity toward the therapeutic goal.

Sherlin et al. (2011) cautioned that shaping should not rely on auto-thresholding because this approach rewards transient shifts in the right direction, whether or not the shift reflects an absolute change from baseline. Auto-thresholding can deliver reinforcement even when clients are not producing the desired behavior, or when they are producing the opposite of it. Additionally, the authors noted that shaping is not applicable to slow cortical potential (SCP) neurofeedback, where there are no normative values to shape toward and only the direction of deviation from baseline (positive or negative) determines training success.
Chaining
Chaining is a procedure from operant conditioning, the form of learning in which behavior is shaped by its consequences (Cooper et al., 2020). In chaining, several discrete components, meaning small and clearly separable actions, are linked in sequence so that together they accomplish a larger goal. Getting dressed in the morning is a familiar example, because some steps must precede others, such as putting on socks before shoes. The order is not arbitrary, since each step sets up the conditions that make the next one possible.
The foundation of any chain is a task analysis, which breaks a complex skill into its component steps and arranges them in a workable order (Cooper et al., 2020). Within the completed chain, each step does double duty. It serves as a conditioned reinforcer, a learned signal that the previous step was performed correctly, and as a discriminative stimulus, a cue that tells the person which response comes next. The final step produces the terminal reinforcer, the meaningful outcome that gives the whole sequence its purpose.
Clinicians typically teach a chain in one of three ways. Forward chaining begins with the first step and adds later steps as each is mastered, while backward chaining starts with the final step so the client experiences the terminal reinforcer early. Total task presentation has the client attempt the entire sequence each session, with support provided on whichever steps still need it. The choice among these methods depends on the skill, the setting, and the learner.
Neurofeedback (NFB), in which clients learn to self-regulate brain activity through real-time feedback, is rarely delivered in isolation (Kerson et al., 2025). It is frequently combined with heart rate variability (HRV) biofeedback, in which the client breathes near their resonance frequency, commonly around six breaths per minute, to amplify the natural oscillation of heart rate and strengthen autonomic regulation (Lehrer & Gevirtz, 2014). It is also paired with cognitive-behavioral self-management and metacognitive techniques, with metacognition referring to the capacity to monitor and direct one's own thinking (Flavell, 1979). Early in care these components are usually trained separately, or only loosely around the NFB sessions.
As a series of sessions nears its end, the trainer can begin to chain these separate skills into a rough sequence that is practical to use outside the clinic. This is a deliberate move toward generalization, the transfer of trained behavior to the everyday settings where it is actually needed (Stokes & Baer, 1977). The goal is a single, rehearsed routine the client can run when life becomes demanding, rather than a set of techniques that remain isolated. Self-instructional training, in which a person guides their own behavior with quiet self-directed speech, helps hold the sequence together (Meichenbaum & Goodman, 1971).
Clinical Application: Putting the Chain to Work
Ray, a veteran finishing a course of NFB combined with HRV biofeedback and brief cognitive-behavioral coaching, often feels swamped when several demands land at once. Near the end of treatment, his trainer helps him assemble a single routine he can run anywhere. When Ray notices the familiar pile-up of rushing thoughts, he first reminds himself that he can focus and slow down, a metacognitive cue that starts the chain. He then breathes at his resonance frequency as he practiced in HRV biofeedback, talks himself through the situation one item at a time using self-instruction, and acts on a single task slowly. He finishes by settling into the calm, focused state he reached when he made the feedback respond during NFB, and he notices the skills working together, the closing metacognitive step that tells him the routine is doing its job.
Cutting Edge: Designing the Whole Learning Environment
Recent work revisiting the learning theory behind neurofeedback and biofeedback argues that outcomes improve when training is treated as a coherent learning environment rather than a collection of isolated procedures (Kerson et al., 2025). Reinforcement timing, schedule, and signal quality determine what the nervous system actually learns, whether the target is an EEG feature or a heart rhythm. Building a practical chain near the end of treatment applies this principle directly, since it converts several separately trained skills into one dependable response. The chain is, in effect, a small learning environment the client carries into daily life.
Key Takeaways
Chaining links discrete, separately learned actions into a single sequence in which each step both signals correct completion of the previous step and cues the next one. A task analysis defines the steps and their order, and clinicians teach the chain through forward chaining, backward chaining, or total task presentation. In neurofeedback practice, chaining lets a client combine NFB, HRV biofeedback, self-instruction, and metacognitive monitoring into one routine that holds together under pressure. Assembling that routine near the end of treatment supports generalization, the transfer of trained skills to the real settings where they matter most.
Discrimination and Generalization
Discrimination and generalization are the ultimate goals of neurofeedback training, and they represent complementary processes that prepare clients for real-world self-regulation. Discrimination teaches clients to recognize the cues that signal when a desired behavior will be reinforced and when it will not. The initial discriminative stimuli include cues provided by the training environment, such as visual animations and auditory tones. A clinician may introduce a controlled stressor following successful skill acquisition to "raise the bar," so that the stressor itself becomes a discriminative stimulus for practicing self-regulation. Over time, discrimination teaches clients to identify and disarm symptom triggers rather than unconsciously reacting to them in daily life.
Generalization refers to variation in how and when a trained behavior occurs. If a trained behavior is painting with oils, response generalization would be painting with watercolors. Stimulus generation would be painting outside instead of in the studio. Temporal generalization would be to continue to paint after instruction has concluded.
Generalization is an important aim of neurofeedback so that the client produces optimal central nervous system states after training in real-life situations. Changes in brain function and structure may underlie part of generalization. Wherever and whenever you go, your brain must be with you. Generalization may also be supported by teaching clients metacognitive skills so that they become insightful about where and when to use neurofeedback and related skills outside training and after its conclusion.
Beyond the ABCs: Establishing Operations and Motivation in Neurofeedback Learning
Most accounts of operant learning rest on the three-term contingency, the sequence in which an antecedent sets the occasion for a behavior that a consequence then follows (Sherlin et al., 2011). These three parts are often called the ABCs, for antecedent, behavior, and consequence. Applied behavior analysis has moved beyond this framework, because the same consequence does not always work as a reinforcer. Michael (1982, 1993) showed that whether a reward strengthens behavior depends on a prior condition that makes the reward worth having at that moment.
That condition is the establishing operation (EO), an antecedent event that temporarily raises the value of a consequence as a reinforcer and increases the current frequency of behavior that has produced it (Michael, 1982, 1993). Food deprivation is the classic example, since hunger makes food reinforcing and evokes behavior that has obtained food before. Aversive stimulation, meaning the presence of an unpleasant condition, works the same way because it makes relief reinforcing. The antecedent, behavior, and consequence chain accomplishes little unless a motivative condition of this kind is already present.
The vocabulary has since been refined. Laraway et al. (2003) folded the EO into the broader motivating operation (MO), which they divided into establishing operations that increase a consequence's effectiveness and abolishing operations that decrease it. Every motivating operation has two effects, a value-altering effect on how reinforcing or punishing a consequence is, and a behavior-altering effect on how often the related behavior occurs right now (Laraway et al., 2003). For a neurofeedback trainer this means the reward screen, the points, and the tones matter only to the degree that some operation has made them worth pursuing in the moment.
Kerson et al. (2025) reaffirm operant conditioning as the foundation of neurofeedback and biofeedback, and they give careful attention to reinforcement schedules, the neurochemistry of reward, placebo effects, and the client and clinician relationship. They do not, however, single out motivating operations as a separate term. For neurofeedback practitioners the concept can feel esoteric, or simply something to assume, yet naming it clarifies why two clients can receive identical feedback and learn at very different rates. The remainder of this section speculates about which motivating operations neurofeedback might recruit.
One candidate is excess neural effort, the costly and inefficient pattern of cortical activity that effortful self-regulation can involve. If that state is even mildly aversive, its presence acts as an establishing operation that makes any reduction in effort reinforcing, much as discomfort makes relief worth working for. This view fits multi-stage accounts in which internal bodily and neural states gradually acquire reinforcing value as learning proceeds (Davelaar, 2018). On this reading the brain is not only chasing points on a screen but also escaping an unpleasant internal condition.
Reinforcers and punishers can also be classified by how they are delivered. Automatic reinforcement arises directly from the behavior itself, with no other person involved, while socially mediated reinforcement is supplied by someone else, such as the trainer who awards points (Vaughan & Michael, 1982). Motivating operations can be socially mediated or induced in the same way, because a trainer's framing, encouragement, and goals can momentarily raise the value of success. The two delivery channels can operate together within a single training session.
Neurofeedback may recruit both channels at once. At the neural level there may be a kind of automatic negative reinforcement, in which the central nervous system settles into a more efficient pattern that lowers aversive effort and is strengthened by that relief, since negative reinforcement strengthens behavior by removing an aversive condition. Layered on top is socially mediated positive reinforcement from the trainer's points and praise, where positive reinforcement strengthens behavior by adding a desirable consequence. Both can feel good because they reduce an unpleasant motivating condition, not only because they add something pleasant.
Consider Maya, a client learning to downtrain excess frontal activity. Early sessions feel effortful, and that effortful state may act as an establishing operation that makes the small drop in activity, and the point it earns, genuinely reinforcing. Because Maya also wants to do well for a trainer she likes, the trainer's encouragement supplies socially mediated reinforcement on top of the automatic relief. As the work becomes easier the establishing operation weakens, which is one reason a warm, motivating relationship helps sustain practice once the early struggle fades.
A second candidate is the client's affiliative or achievement need, the wish to connect with the trainer or to succeed by earning more points. When that need is present, the trainer's approval and the rising score become genuine reinforcers, which gives a behavior-analytic argument for the strong therapeutic alliance that Kerson et al. (2025) emphasize. Framing, rapport, and goal setting then become ways of installing and maintaining helpful motivating operations rather than background niceties. Read together, these ideas show how applied behavior analysis and basic brain science can be joined in a single account of why neurofeedback works.
Operant learning in neurofeedback depends on more than antecedents, behaviors, and consequences. A motivating operation, such as excess neural effort or an affiliative need, must make the feedback worth pursuing before reinforcement can do its work. Neurofeedback plausibly combines automatic negative reinforcement at the neural level with socially mediated positive reinforcement from the trainer, and both relieve an unpleasant motivating condition. Attending to these motivating operations gives a principled reason to value reinforcer design, signal timing, and the therapeutic relationship.

Check out the TED-Ed video, The Difference Between Classical and Operant Conditioning.
Operant conditioning modifies voluntary behavior through its consequences and serves as the primary learning mechanism in neurofeedback. Clinicians use positive and negative reinforcement, punishment, and shaping to teach clients self-regulation of neural activity. Reinforcement parameters (including schedule type, timing, and artifact control) critically determine training effectiveness. Discrimination and generalization work together to help clients transfer learned self-regulation skills from the clinic to real-world settings.
Check Your Understanding
- How does operant conditioning differ from classical conditioning in its approach to modifying behavior?
- Why is it important that reinforcement in neurofeedback be delivered within 250 to 350 ms of the desired behavior?
- What are the risks of using auto-thresholding for shaping in neurofeedback training?
- How do EEG artifacts interfere with the operant conditioning process in neurofeedback?
- Why are variable reinforcement schedules preferred over continuous reinforcement as neurofeedback training progresses?
Nonassociative Learning
This section covers two simpler forms of learning (habituation and sensitization) and their practical implications for neurofeedback training. Nonassociative learning is a basic learning process in which the strength of a response to a stimulus changes with repeated exposure, without forming associations between paired events. Habituation and sensitization are its two primary forms.
In habituation, our response to an unchanging, harmless stimulus weakens with repeated exposure. This process can quietly undermine the transfer of neurofeedback skills to everyday life. For example, clients may quickly tune out visual reminders (such as colored dots) meant to prompt self-regulation practice. One practical strategy to counter habituation is to randomly vary the color and shape of these prompts, maintaining their novelty and effectiveness. Habituation may also be an important consideration for reinforcement in neurofeedback, leading a trainer to vary the reinforcing stimuli.
In sensitization, our response to a broad range of stimuli intensifies following exposure to a single powerful stimulus. After a traumatic experience such as an earthquake, for example, a person's reaction to movement or noise may become exaggerated. Sensitization is clinically relevant because it can amplify physiological and emotional reactivity in clients with trauma histories, making it an important consideration when designing neurofeedback protocols.

Observational Learning
This section covers how observational learning contributes to skill acquisition in neurofeedback and related training. Observational learning allows us to rapidly acquire or refine a skill by watching others perform it. This social learning process is highly efficient because it bypasses the slower, riskier path of trial-and-error learning. We benefit from the outcomes others have already experienced without having to encounter those consequences ourselves.
Observational learning is inherently interactive. Consider a music student who listens to a teacher play a violin passage, attempts to reproduce the same notes, and then compares the two performances. Through repeated cycles of observation, practice, and comparison, the student refines their technique until it matches the original model. Feedback drives this iterative refinement. In neurofeedback, a similar dynamic applies when clinicians demonstrate breathing techniques or when clients observe how their brain activity responds to different ways of thinking or self-instruction that the trainer has verbally demonstrated.

Critical Elements in Neurofeedback Training
This section covers the eight critical elements that determine the effectiveness of neurofeedback training: readiness, repetition, reinforcement, primacy, recency, intensity, freedom, and resources. Each element draws on established learning principles and has direct implications for how you structure sessions and support clients.
Readiness
Readiness refers to a client's preparation for training and encompasses both concentration and enthusiasm. As M. Tracy (personal communication, 2018) observed, "Individuals learn best when they are physically, mentally, and emotionally ready to learn, and do not learn well if they see no reason for learning." Readiness requires adequate rest and nutrition along with a positive, supportive environment. Client education that clearly explains the training process, defines goals and outcomes, and links training to personally relevant benefits enhances readiness from the first session.

Conversely, poor motivation, a lack of understanding about potential benefits, and biopsychosocial barriers can all impair readiness. Significant impediments include a chaotic or traumatic environment, inadequate rest and nutrition, developmental delays, limited resources, and traumatic brain injury or other medical conditions. Clinicians who assess and address these factors before training begins position their clients for stronger outcomes.
Repetition (Exercise)
Practice performed both within and outside the clinic promotes client engagement and supports the transfer of training to everyday life. Effective training recognizes the principles of brain plasticity and the physiological requirements for skill acquisition and consolidation. Practice periods should range from 10 to 30 minutes and include a minimum of 20 repetitions to produce meaningful change. Encouraging home practice between sessions extends the benefit of in-clinic work and reinforces emerging self-regulation skills.

Reinforcement (Effect)
For reinforcement to be effective, it must be personally desirable to the client. Clinicians can verify this by observing how specific reinforcers affect engagement, motivation, and performance. Rewards that are intrinsically meaningful accelerate the development of mastery and improve long-term retention. Clear evidence of success builds client confidence and reduces frustration, while encouragement from staff and family sustains progress through difficult periods.
Sherlin et al. (2011) speculated that secondary reinforcement, such as monetary rewards or redeemable points, might accelerate the learning of self-regulation skills during neurofeedback. They cautioned, however, that such secondary reinforcement should be contingent on demonstrated EEG changes, not simple attendance. Reinforcement must also occur "immediately" to ensure that the brain correctly pairs the consequence with the desired behavior that preceded it. Early operant research established that the optimal delay between a behavior and its reinforcement is less than 250 to 350 milliseconds (Felsinger et al., 1947; Grice, 1948).
The practical implication is clear: faster delivery of reinforcement following the desired behavior reduces the time required for skill acquisition. This means that shorter EEG filter response times produce better training outcomes (Sherlin et al., 2011, p. 298). As Miller (2006) stated, "The more immediate the delivery of the reinforcer after the behavior, the more effective the reinforcer" (p. 233).

One additional caution deserves attention. Egner and Sterman (2006) warned that neurofeedback training "should stress exercise rather than entertainment" because overly complex games may distract clients from linking their brain responses to the reinforcement signal. When visually salient game elements compete for the client's attention, the operant learning process can be compromised.
Primacy
Think of neurofeedback training like building a house: you need a strong foundation before adding walls and a roof. Client education should begin with the core principles that will anchor all subsequent learning. Like home construction, skill acquisition should proceed in a logical, stepwise fashion that builds on prior experience. When clients successfully master initial skills, they gain the confidence to tackle more complex ones.

Recency
Clients more readily recall material learned most recently, a well-established finding in memory research. The combination of recency and repetition strengthens the retention of self-regulation skills. Session frequency matters because more frequent training sessions mean that the pairing of skill practice with reinforcement remains fresh. This recency effect makes a compelling case for scheduling sessions as close together as the client's circumstances permit.

Intensity
The brain is fundamentally a difference and intensity detector, allocating greater attention and processing resources to novel and intense events. This principle suggests that pairing neurofeedback with vivid, experiential exercises can facilitate self-regulation skill retention. Adjunctive activities that engage multiple senses or evoke emotional responses may leave stronger memory traces, reinforcing the lessons of the training session.

Freedom
Active, willing participation facilitates learning, while coercion, compulsion, and forced participation inhibit it. Reward systems are only effective when they foster genuine engagement. Clients who internalize training goals and outcomes as their own develop stronger self-motivation and greater perceived self-efficacy, both of which predict better long-term outcomes.

Resources (Requirement)
Effective neurofeedback professionals begin with skills already in the client's repertoire and build from there. For example, heart rate variability (HRV) biofeedback capitalizes on a client's existing breathing skills and then shapes the mechanics and rate of respiration toward a therapeutic target. Shaping, the gradual reinforcement of successive approximations of a target behavior, is the mechanism by which new skills are added to a client's repertoire. Starting from a foundation of existing competencies prevents frustration and supports steady progress.

Olton and Noonberg (1980) proposed a practical guideline: raise performance goals when a client succeeds more than 70% of the time, and lower them when success drops below 30%. This range keeps clients challenged without overwhelming them.
During neurofeedback training, the trainer should remain in the room with the client rather than relying on automatic thresholds. When the reinforcement rate stays too lean and frustrating for too long, the trainer can relax the threshold to restore a rewarding pace. The trainer then gradually shapes the client's EEG performance back toward its previous, more demanding level.

Effective neurofeedback training depends on eight interconnected elements: client readiness, consistent repetition, timely and personally meaningful reinforcement, a strong foundational approach (primacy), frequent sessions (recency), novel and intense learning experiences, active client participation (freedom), and building upon existing skills (resources). Together, these elements optimize skill acquisition and support the transfer of self-regulation to everyday life.
Check Your Understanding
- Why is client readiness important for successful neurofeedback training, and what factors can impair it?
- How does the principle of primacy apply to the structure of neurofeedback training sessions?
- Why do Olton and Noonberg recommend adjusting performance goals based on the client's success rate?
- How does the principle of freedom relate to client motivation and self-efficacy in neurofeedback?
Designing the Learning Environment
Everything you have read so far treats learning as something that happens inside the client. Kerson, Sherlin, and Davelaar (2025) recently revisited the 2011 framework you met earlier in this chapter and shifted the emphasis outward. Their central argument is that neurofeedback outcomes improve when you stop treating feedback as mere information and start treating it as an engineered learning environment. In this view, your protocol is not only a physiological target. It is a training ecosystem that either supports stable learning or quietly confuses it.

This reframe explains several puzzles you will meet in the clinic. Why does a client perform beautifully in session yet cannot reproduce the state at home? Why do gains plateau even when the client is motivated and compliant? Kerson and colleagues (2025) answer that these patterns often reflect basic learning variables, including reinforcement consistency, timing, and the client's ability to recognize and re-enter the trained state on demand.
Two Tracks of Learning
Kerson et al. (2025) describe training as running on two tracks at once. The first track is explicit learning, a conscious process in which the client deliberately selects strategies and knows what is being practiced, such as softening the gaze, relaxing the jaw, or pacing the breath. The second track is implicit operant learning, an unconscious process in which neural patterns are strengthened through reinforcement even though the client cannot articulate how the change occurred.
Most clients improve through some blend of both tracks, and the balance shifts with age, cognitive style, symptom profile, and even how tired the client is that day. This has a practical consequence for you. When a client says, "I don't know how I did it," that is often healthy implicit learning rather than a problem. The real warning sign appears when success looks random both to the client and in the data, with reward rates swinging widely despite similar effort, because that pattern points to a learning-environment problem rather than a motivational one (Kerson et al., 2025).
Reinforcement Schedules Are Clinical Levers
A reinforcement schedule is the rule that determines when feedback is delivered. Some systems deliver continuous reinforcement, providing feedback each time an EEG state persists for a set interval, such as half a second, or for as long as the EEG signal remains above or below threshold. Other systems deliver variable reinforcement, in which the feedback grows stronger or weaker as the magnitude of the EEG or HEG signal itself changes. Kerson et al. (2025) treat it as a clinical lever because it changes what the client actually experiences.
A continuously variable reinforcement (i.e., intensity of the feedback changes with level of EEG or HEG signal) feels smooth and responsive, so the client can experiment and notice what increases reward. An interval-sampled system that looks at fixed or variable moments in time to decide whether or not to present feedback/reinforcement at that time may make the feedback feel stingy or inconsistent even when the client is intermittently producing the target state. You can therefore treat reward feel, the client's subjective sense of how responsive and predictable the feedback is, as a diagnostic signal. When an engaged, competent client reports that the reward seems disconnected from their effort, suspect a schedule, threshold, or artifact problem before you assume resistance or poor insight. For these reasons, the trainer should remain “connected” to the client in the room.
When Training Drifts Toward Sham
In research, a sham condition uses random reinforcement, a noncontingent pattern in which rewards are only weakly tied to the client's real-time signal. Kerson and colleagues (2025) make the unsettling point that routine sessions can drift toward sham-like conditions whenever reinforcement quietly loses its contingency. Picture Maria, a motivated client whose frontal electrode has slipped just enough to introduce slow drift. The system keeps delivering rewards, but they no longer track her brain state, and the task has become a slot machine.
The usual culprits are mundane. EEG artifacts can inflate or suppress the very metrics you reward, muscle tension can masquerade as high-frequency activity, eye movements can contaminate frontal sites, and line noise can add rhythmic contamination the client cannot control. When that happens, the client may undergo accidental training, an unintended process in which reinforcement strengthens artifacts or compensatory maneuvers rather than the target state. To guard against this, track reinforcement integrity as a routine clinical variable and ask plainly whether the client is being rewarded for the thing you think you are rewarding (Kerson et al., 2025).
When you suspect that reward has lost its contingency, make your uncertainty visible in the workflow rather than pushing harder. Tighten signal-quality checks, increase artifact monitoring, and consider temporarily shifting to a simpler, cleaner channel such as respiration pacing or peripheral temperature while you troubleshoot the EEG. If the client suddenly "finds it" once you simplify the task or raise reward probability, the learning environment was probably too hard or too noisy all along.
Why Timing Is Part of the Message
Feedback is not only about whether a reward arrives but also about when it arrives. Reinforcement learning depends on tight coupling between a successful response and its consequence, so a reward that comes late can strengthen whatever happened closest to it, whether that is a compensatory strategy, an artifact, or a brief unrelated change (Kerson et al., 2025; Valentin et al., 2014). This is why latency, the time delay between a physiological event and the delivery of feedback, deserves to be treated as clinically meaningful rather than an invisible technical detail.
Every platform carries a chain of delays that includes signal acquisition, filtering, artifact handling, feature computation, threshold comparison, and the visual or auditory display. Even when each step is fast, total latency can creep upward. You met this principle earlier in the finding that reinforcement works best when delivered within 250 to 350 milliseconds of the desired behavior. When clients tell you the feedback feels "behind," or when they can boost reward only through abrupt efforts such as tensing or breath holding, take the report seriously and look for a timing problem.
Expectancy and the Ethics of Hope
Clients never arrive as blank slates. They bring hope, skepticism, fear, and a personal story about what their symptoms mean, and those beliefs shape attention, effort, and persistence. Kerson et al. (2025) fold this into the learning environment under the heading of expectancy, a client's belief about what treatment will do that can influence motivation, perceived control, and even symptom experience. Expectancy overlaps with the placebo effect, a change in symptoms driven by meaning and perceived control rather than a specific active ingredient (Thibault et al., 2018).
The goal is not to eliminate expectancy but to harness it ethically and keep it aligned with genuine skill acquisition. You can do this by offering a credible rationale, making the task understandable, and explaining that progress is usually nonlinear, with early gains in state control that later consolidate into lasting change. A useful stance is to treat hope as fuel and data quality as steering, staying encouraging while still insisting on clean signals and honest interpretation. That balance prevents the common failure in which optimism masks a weak learning environment, so training looks busy without producing stable skills.
Computational researchers increasingly model neurofeedback as a formal reinforcement learning problem, a framework in which behavior is shaped by feedback and by prediction error, the difference between what the nervous system expected and what actually occurred (Lubianiker et al., 2022). This lens helps explain why contingency and timing matter so much, because a reward that does not follow the intended state generates a misleading prediction error and teaches the wrong lesson.
Becoming a Learning Coach
One of the most practical threads in the paper is the shift from technician to learning coach. Kerson et al. (2025) emphasize cultivating phenomenological awareness, the clinician-supported ability to notice, describe, and make meaning of what the target state feels like and how to return to it. This is how you reduce the familiar complaint, "I can do it in session but not in life."
You can build this awareness without turning sessions into therapy talk. After a good run, ask the client to describe the state in sensory language, drawing on interoception, the sense of internal states such as heart rhythm, breathing, and muscle tension. Ask what changed in their breathing, posture, gaze, or emotional tone, and what the smallest helpful action was. If the client cannot describe it, offer options rather than forcing introspection, and over time they will build a personal map of the state they are learning to find.
Practical Upgrades to Your Training Environment
The simplest way to apply this paper is to treat each session as a learning experiment with a few controllable variables. Start with reward probability, because a task that is too hard at the outset never gives the client enough successful trials to learn from. Many clients benefit from an early phase of frequent rewards that lets the nervous system discover the pathway, followed by gradual tightening through shaping, the reinforcement of successive approximations toward the target (Kerson et al., 2025).
Next, stabilize what success means. Threshold setting, the process of choosing the parameter that defines a rewardable response, can quietly sabotage learning when it drifts. Thresholds that adjust too aggressively create a moving target, while thresholds that never adjust let the client hit a ceiling where improvement no longer changes the reward. Adjust them deliberately and in small steps, and tell the client why, with something as plain as, "We are making this slightly harder so your brain keeps learning."
Finally, build generalization on purpose. Transfer is the deliberate carrying of a self-regulation skill into daily life by practicing it with reduced or no feedback, and you can rehearse it inside a session through transfer trials that briefly turn feedback off and then back on to check whether the client can regain the state. Watch for accidental training during these upgrades, because a client who discovers that jaw tension, breath holding, or harder staring increases reward will keep doing it, training strain instead of self-regulation (Kerson et al., 2025).
Kerson, Sherlin, and Davelaar (2025) reframe neurofeedback as an engineered learning environment in which reinforcement schedules, timing, and signal integrity decide what the nervous system actually learns. Outcomes improve when you treat reward contingency as a central variable, minimize conditions that make reinforcement effectively random, and keep feedback latency short enough to strengthen the intended state. Lasting benefit depends on bridging implicit operant learning with the client's ability to recognize and re-enter the trained state, supported by brief attention to phenomenological awareness and deliberate transfer practice.
Check Your Understanding
- What does it mean to treat neurofeedback as an engineered learning environment rather than as a stream of information?
- How can you distinguish healthy implicit operant learning from a learning-environment problem when a client says, "I don't know how I did it"?
- Why can a routine session drift toward sham-like conditions, and how would you monitor reinforcement integrity?
- How does feedback latency shape what the nervous system learns, and what client reports suggest a timing problem?
- What is the difference between explicit learning and implicit operant learning, and why does phenomenological awareness support generalization?
Assignment
Now that you have completed this unit, which sounds do you prefer when you have succeeded during neurofeedback training? Which visual displays are more motivating for you?
Glossary
abolishing operation (AO): a motivating operation that momentarily decreases the effectiveness of a consequence as a reinforcer or punisher and reduces the behavior that consequence has maintained.
accidental training: an unintended learning process in which the client is reinforced for artifacts, compensatory maneuvers, or other non-target behaviors because the feedback is not tightly tied to the intended physiological state.
affiliative or achievement need: a client's motivation to connect with the trainer or to succeed, which can function as a motivating operation that makes praise and points reinforcing.
associative learning: a learning process in which we create connections between stimuli, behaviors, or stimuli and behaviors.
automatic reinforcement: reinforcement produced directly by a behavior itself, without delivery by another person; it can be positive, by adding a desirable result, or negative, by removing an aversive one.
aversive stimulation: the presence of an unpleasant condition that functions as a motivating operation by making its removal reinforcing.
behavior-altering effect: the effect of a motivating operation on the current frequency of behavior related to a given consequence.
aversive stimulation: the presence of an unpleasant condition that functions as a motivating operation by making its removal reinforcing.
backward chaining: teaching method in which the trainer completes the early steps and the client performs the final step first, then takes on earlier steps as each one is mastered, so the rewarding end of the sequence is experienced from the start.
chaining: teaching method in which the trainer completes the early steps and the client performs the final step first, then takes on earlier steps as each one is mastered, so the rewarding end of the sequence is experienced from the start.
classical conditioning: an unconscious associative learning process that builds connections between paired stimuli that follow each other in time.
conditioned response (CR): in classical conditioning, a response to a conditioned stimulus (CS). For example, salivation in response to a bell.
conditioned stimulus (CS): in classical conditioning, a stimulus that elicits a response after training. For example, a bell after pairing with food.
continuous reinforcement: reinforcement of every desired behavior, helpful during the early stage of skill acquisition.
discrimination (classical conditioning): a response to the original CS, but not to one that resembles it. For example, salivation to a high-pitched bell, but not to a low-pitched bell.
discrimination (operant conditioning): the performance of the desired behavior in one context, but not another. For example, increasing sensorimotor rhythm (SMR) activity at bedtime, but not during a morning commute.
discriminative stimuli: in operant conditioning, the identifying characteristics of a situation (the physical environment and physical, cognitive, and emotional cues) that teach us when to perform operant behaviors. For example, a traffic slowdown could signal a client to practice effortless breathing.
EEG artifacts: false signals that masquerade as brain electrical activity.
establishing operation (EO): an antecedent event that temporarily increases the value of a consequence as a reinforcer and raises the frequency of behavior that has produced it (Michael, 1982, 1993).
excess neural effort: a proposed motivating operation in neurofeedback in which costly, inefficient cortical activity makes a reduction in effort reinforcing.
expectancy: a client's belief about what treatment will do, which can shape attention, motivation, perceived control, and symptom experience, thereby influencing learning and outcomes.
explicit learning: a conscious learning process in which the client deliberately selects strategies and is aware of what is being practiced.
extinction (classical conditioning): reducing a CR when the UCS no longer follows the CS. For example, less salivation when food no longer follows a bell.
extinction (operant conditioning): a reduction in response frequency when the desired behavior is no longer reinforced. For example, a client practices less when the clinician ceases to praise this behavior.
forward chaining: a teaching method that begins with the first step of the sequence and adds each later step as the previous one is mastered.
generalization (classical conditioning): response to stimuli that resemble the original CS. For example, salivation to both a low- and high-pitched bell.
generalization (operant conditioning): the performance of the desired behavior in multiple contexts. For example, increasing low-beta activity during both classroom lecture and golf practice.
habituation: a nonassociative learning phenomenon in which responses to unchanging and harmless stimuli decrease.
implicit operant learning: an unconscious learning process in which neural patterns are strengthened through reinforcement without the learner being able to articulate how the change occurred.
interoception: the sense of internal bodily states such as heart rhythm, breathing, muscle tension, and autonomic arousal.
latency: the time delay between a physiological event and the delivery of feedback, which can affect what is learned.
learning: the process by which we acquire new information, patterns of behavior, or skills.
metacognition: awareness and regulation of one's own thinking, including monitoring understanding and selecting strategies to guide cognitive effort.
motivating operation (MO): the general term for an antecedent that alters both the effectiveness of a consequence and the current strength of related behavior, subsuming establishing and abolishing operations.
negative punishment: in operant conditioning, a process that decreases or eliminates an undesirable behavior by removing what is desired. For example, a child's oppositional behavior could result in a clinician turning off a popular game.
negative reinforcement: in operant conditioning, a process that increases the frequency of the desired behavior by making the avoidance, termination, or postponement of an unwanted outcome contingent on acting. For example, an athlete's anxiety decreases by shifting from high beta to low beta, rewarding this self-regulation.
neutral stimulus (NS): in classical conditioning, a stimulus that does not elicit a response. For example, a bell before pairing with food.
nonassociative learning: a simple learning process in which the strength of the response to a stimulus changes with repeated exposure.
observational learning: learning by observing others. For example, a fitness client learns to stretch by watching a personal trainer demonstrate the technique.
operant conditioning: an unconscious associative learning process that modifies an operant behavior, voluntary behavior that operates on the environment to produce an outcome by manipulating its consequences.
partial reinforcement schedules: reinforcement schedules where the desired behavior is only reinforced some of the time.
phenomenological awareness: a clinician-supported ability to notice, describe, and make meaning of the subjective experience of the target state.
placebo effect: a change in symptoms or performance driven by expectancy, meaning, and perceived control rather than by a specific active ingredient.
positive punishment: in operant conditioning, a process that decreases or eliminates an undesirable behavior by associating it with unwanted consequences. For example, a child's increased fidgeting dims a favorite movie and lowers the sound.
positive reinforcement: in operant conditioning, a process that increases the frequency of a desired behavior by making a desired outcome contingent on performing the action. For example, a movie plays when a client increases low-beta and decreases theta activity.
prediction error: the difference between what the nervous system expects and what actually occurs, which drives learning in reinforcement-learning models.
random reinforcement: a noncontingent feedback pattern in which rewards are only weakly related to the learner's real-time signal, as in a sham condition.
readiness: preparation for training involving concentration and enthusiasm.
reinforcement learning: a learning framework in which behavior is shaped by feedback and prediction errors that update the learner's expectations.
reinforcement schedule: a rule that determines when and how feedback rewards are delivered in response to performance.
reward feel: a client's subjective sense of how responsive and predictable the feedback is, meaning whether rewards seem clearly tied to their effort and internal state changes.
self-instructional training: a cognitive-behavioral method in which a person learns to guide their own actions through deliberate, self-directed speech.
sensitization: a nonassociative learning phenomenon in which there is an exaggerated reaction to diverse stimuli following exposure to a single powerful stimulus.
shaping: the method of successive approximations that teaches clients new behaviors by progressively raising reinforcement criteria.
socially mediated reinforcement: reinforcement delivered by another person, such as a trainer who awards points or offers praise.
spontaneous recovery: in classical conditioning, the reappearance of an extinguished CR following a rest period. For example, salivation following its disappearance.
stimulus discrimination: in classical conditioning, when a conditioned response (CR) is elicited by one conditioned stimulus (CS) but not by another. For example, your blood pressure increases during a painful dental procedure but not during an uncomfortable blood draw.
stimulus generalization: in classical conditioning, when stimuli that resemble a conditioned stimulus (CS) elicit the same conditioned response (CR). For example, when your blood pressure increases during a painful dental procedure and an uncomfortable blood draw. In operant conditioning, the occurrence of a trained behavior in settings or contexts different from the one in which it was trained.
temporal generalization: the persistence of a trained behavior across time, specifically its continuation after instruction or training has concluded.
three-term contingency: the basic unit of operant learning, consisting of an antecedent, a behavior, and a consequence.
threshold setting: the process of choosing the parameter that defines what counts as success for reward delivery in a feedback system.
transfer: the deliberate process of carrying a trained self-regulation skill into daily life by practicing it with reduced or no feedback in contexts that resemble real-world demands.
transfer trials: a practice method that reduces or removes feedback so the learner must reach the target state under more naturalistic conditions.
unconditioned response (UCR): in classical conditioning, a response to a UCS that elicits a response without training. For example, salivation in response to food.
unconditioned stimulus (UCS): in classical conditioning, a stimulus that elicits a response without training. For example, food.
value-altering effect: the effect of a motivating operation on how reinforcing or punishing a consequence is at a given moment.
variable reinforcement schedules: reinforcement schedules where reinforcement occurs after a variable number of responses or following a variable duration of time.
References
Albino, R., & Burnand, G. (1964). Conditioning of the alpha rhythm in man. Journal of Experimental Psychology, 67(6), 539-544. https://doi.org/10.1037/h0042695
Cacioppo, J. T., & Freberg, L. A. (2016). Discovering psychology (2nd ed.). Cengage Learning.
Clemente, C. D., Sterman, M. B., & Wyrwicka, W. (1964). Post-reinforcement EEG synchronization during alimentary behavior. Electroencephalography and Clinical Neurophysiology, 16, 355-365. https://doi.org/10.1016/0013-4694(64)90069-0
Cooper, J., Heron, T., & Heward, W. (2019). Applied behavior analysis (3rd ed.). Pearson Education.
Durup, G., & Fessard, A. I. (1935). Blocking of the alpha rhythm. L'année Psychologique, 36(1), 1-32.
Egner, T., & Sterman, M. B. (2006). Neurofeedback treatment of epilepsy: From basic rationale to practical application. Expert Review of Neurotherapeutics, 6(2), 247-257.
Felsinger, J. M., Gladstone, A. I., Yamaguchi, H. G., & Hull, C. L. (1947). Reaction latency (StR) as a function of the number of reinforcements (N). Journal of Experimental Psychology, 37(3), 214-228. https://doi.org/10.1037/h0055587
Flavell, J. H. (1979). Metacognition and cognitive monitoring: A new area of cognitive-developmental inquiry. American Psychologist, 34(10), 906–911. https://doi.org/10.1037/0003-066X.34.10.906
Grice, G. R. (1948). The relation of secondary reinforcement to delayed reward in visual discrimination learning. Journal of Experimental Psychology, 38(1), 1-16. https://doi.org/10.1037/h0061016
Jasper, H., & Shagass, C. (1941). Conditioning the occipital alpha rhythm in man. Journal of Experimental Psychology, 28(5), 373-387. https://doi.org/10.1037/h0056139
Kamiya, J. (2011). The first communications about operant conditioning of the EEG. Journal of Neurotherapy, 15(1), 65-73. https://doi.org/10.1080/10874208.2011.545764
Kerson, C., Sherlin, L. H., & Davelaar, E. J. (2025). Neurofeedback, biofeedback, and basic learning theory: Revisiting the 2011 conceptual framework. Applied Psychophysiology and Biofeedback. Advance online publication. https://doi.org/10.1007/s10484-025-09756-4
Knott, J. R. (1941). Electroencephalography and physiological psychology: Evaluation and statement of problem. Psychological Bulletin, 38(10), 944-975. https://doi.org/10.1037/h0059465
Laraway, S., Snycerski, S., Michael, J., & Poling, A. (2003). Motivating operations and terms to describe them: Some further refinements. Journal of Applied Behavior Analysis, 36(3), 407–414. https://doi.org/10.1901/jaba.2003.36-407
Loomis, A. L., Harvey, E. N., & Hobart, G. (1936). Electrical potentials of the human brain. Journal of Experimental Psychology, 19, 249. https://doi.org/10.1037/h0062089
Lubianiker, N., Paret, C., Dayan, P., & Hendler, T. (2022). Neurofeedback through the lens of reinforcement learning. Trends in Neurosciences, 45(8), 579-593. https://doi.org/10.1016/j.tins.2022.03.008
Malott, R. W., & Shane, J. T. (2013). Principles of behavior (7th ed.). Pearson Prentice Hall.
Michael, J. (1982). Distinguishing between discriminative and motivational functions of stimuli. Journal of the Experimental Analysis of Behavior, 37(1), 149–155. https://doi.org/10.1901/jeab.1982.37-149
Michael, J. (1993). Establishing operations. The Behavior Analyst, 16(2), 191–206. https://doi.org/10.1007/BF03392623
Meichenbaum, D. H., & Goodman, J. (1971). Training impulsive children to talk to themselves: A means of developing self-control. Journal of Abnormal Psychology, 77(2), 115–126. https://doi.org/10.1037/h0030773
Miller, L. K. (2006). Principles of everyday behavior analysis (4th ed.). Wadsworth.
Miltenberger, R. G. (2016). Behavior modification: Principles and procedures. Cengage Learning.
Olton, D. S., & Noonberg, A. R. (1980). Biofeedback: Clinical applications in behavioral medicine. Prentice-Hall, Inc.
Pavlov, I. P. (1927). Conditioned reflexes. Oxford University Press.
Sherlin, L. H., Arns, M., Lubar, J., Heinrich, H., Kerson, C., Strehl, U., & Sterman, M. B. (2011). Neurofeedback and basic learning theory: Implications for research and practice. Journal of Neurotherapy, 15(4), 292-304. https://doi.org/10.1080/10874208.2011.623089
Sitaram, R., Sanchez-Corzo, A., Vargas, G., Cortese, A., El-Deredy, W., Jackson, A., & Fetz, E. (2024). Mechanisms of brain self-regulation: Psychological factors, mechanistic models and neural substrates. Philosophical Transactions of the Royal Society B: Biological Sciences, 379(1915), Article 20230093. https://doi.org/10.1098/rstb.2023.0093
Sterman, M. B., LoPresti, R. W., & Fairchild, M. D. (1969). Electroencephalographic and behavioral studies of monomethyl hydrazine toxicity in the cat (Technical Report AMRL-TR-69-3). Aerospace Medical Research Laboratory.
Stokes, T. F., & Baer, D. M. (1977). An implicit technology of generalization. Journal of Applied Behavior Analysis, 10(2), 349–367. https://doi.org/10.1901/jaba.1977.10-349
Thibault, R. T., Veissière, S., Olson, J. A., & Raz, A. (2018). Treating ADHD with suggestion: Neurofeedback and placebo therapeutics. Journal of Attention Disorders, 22(8), 707-711. https://doi.org/10.1177/1087054718770012
Thorndike, E. L. (1913). Educational psychology: Briefer course. Teachers College.
Travis, L. E., & Egan, J. P. (1938). Conditioning of the electrical response of the cortex. Journal of Experimental Psychology, 22(6), 524-531. https://doi.org/10.1037/h0056243
Valentin, V. V., Maddox, W. T., & Ashby, F. G. (2014). A computational model of the temporal dynamics of plasticity in procedural learning: Sensitivity to feedback timing. Frontiers in Psychology, 5, Article 643. https://doi.org/10.3389/fpsyg.2014.00643
Vaughan, M. E., & Michael, J. L. (1982). Automatic reinforcement: An important but ignored concept. Behaviorism, 10(2), 217–227.
Wyrwicka, W., & Sterman, M. B. (1968). Instrumental conditioning of sensorimotor cortex EEG spindles in the waking cat. Physiology and Behavior, 3(5), 703-707. https://doi.org/10.1016/0031-9384(68)90139-X
Return to Top